作者丨欲扬先抑@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/506317516
编辑丨极市平台

论文地址:https://arxiv.org/abs/2201.03545
代码地址:https://github.com/facebookresearch/ConvNeXt
这篇文章是一篇“文艺复兴”工作。读起来的时候能感觉到作者对于ConvNet无限的热爱,尤其是在读Introduction部分的时候。通篇读下来,作者的核心论点,同时也是最吸引我的一句话是“the essence of convolution is not becoming irrelevant; rather, it remains much desired and has never faded”。整篇文章写的非常漂亮。
Introduction
作者在Introduction部分里,从ConvNet的前世今生开始讲起,并且在第二段就表明了一个观点:“The full dominance of ConvNets in computer vision was not a coincidence”。 确实,卷积神经网络在transformer诞生前称霸了整个计算机视觉领域,而作者的这篇工作就是让ConvNet重新在视觉领域大放异彩!
作者认为ViT之所以效果好,是因为它是一个大模型,能够适配大量数据集,这使得它能够在分类领域中领先ResNet一大截。但是CV中不仅仅只有分类任务,对于大部分的CV任务,利用的都是滑动窗口,全卷积这样的方式。同时作者指出了ViT的一个最大问题:ViT中的global attention机制的时间复杂度是平方级别的,对于大图片来讲,计算效率会很低。
让作者更佳坚信卷积不会被时代淘汰的一个很关键的原因是Swin Transformer的出现,这种利用local window attention的机制更加充分地证明了卷积这种提取局部的特征信息的作法一定是work的,且一定能发挥应有的性能。同时,作者也指出当下大家都去研究transformer是因为transformer的效果超越了利用ConvNet做的视觉任务。因此,整篇工作,作者就是为了探究构建一个ConvNet要看看它的极限到底在哪里。
Modernizing a ConvNet: a Roadmap
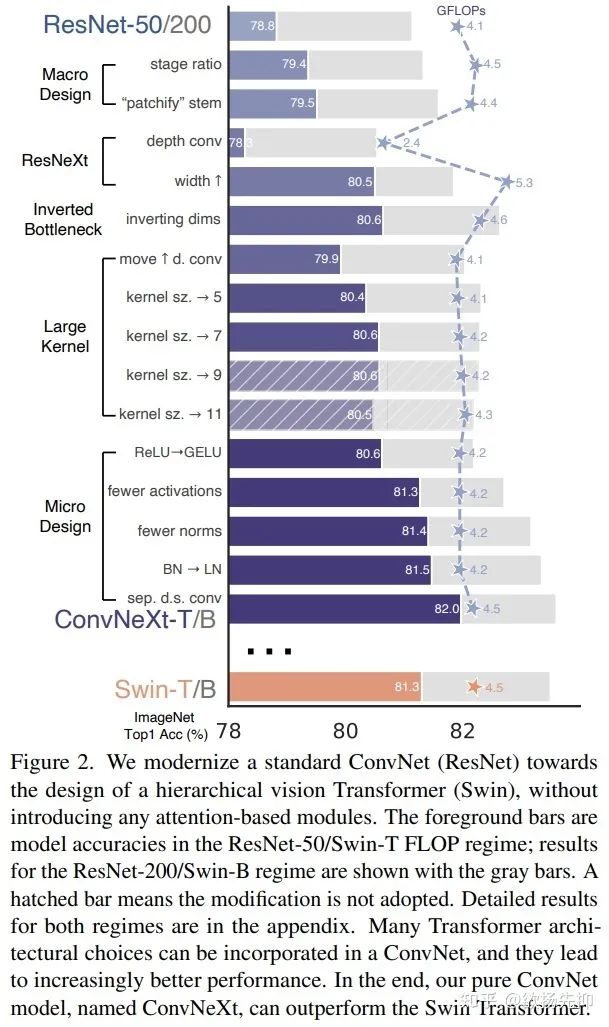
作者从ResNet-50开始,研究了一系列“network modernization”操作,通过FLOPs和在ImageNet-1K上的Acc这两个指标来验证改进操作是否有效。下图是一些列操作的结果。
Training Techniques
首先是训练技巧上更新变成与DeiT相似,作者将epochs从90改成了300,利用AdamW优化器,数据增广手段包括:Mixup,Cutmix,RandAugment,Random Erasing,regularization schemes(包括Stochastic Depth和Label Smoothing)。经过这个改进,ResNet-50从76.1%提升到78.8% 。
Macro Design
Changing stage compute ratio: 作者仿照Swin的层级设计中的compute ratio 1:1:3:1,将compute ratio由原来的(3, 4, 6, 3)变为(3, 3, 9, 3),经过这个改进Acc由78.8%提升到79.4% 。
Changing stem to "Patchify": 作者仿照ViT,进行了non-overlapping的convolution。是利用 ,stride 的卷积进行操作,Acc由79.4%提升到79.5% 。
ResNeXt-ify
在这一部分作者尝试采用ResNeXt的思路,对FLOPs和Acc进行一个trade-off。核心是grouped convolution。作者采用的是depthwise convolution也就是卷积数与通道数相等。这里也提到了ViT就是depthwise conv和 conv进行channel mixing,也同时在spatial维度上进行特征融合。depthwise这种操作在MobileNet和Xception上都有用到。利用它可以降低FLOPs。作者同时将channel数量从64变为了和Swin-T一样的96.这使得Acc提到了80.5%。FLOPs提升到了 (5.3G) 。
Inverted Bottleneck
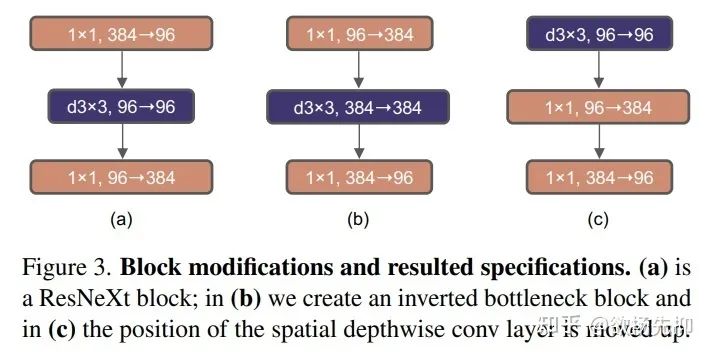
如Fig3所示,作者作者修改了Bottleneck的结构如(b)所示,从80.5%提升到了80.6% 。
Large Kernel Sizes
作者为了与Swin同步,想选用大的kernel size,因为Swin中最小也是 ,也比ResNet kernel size 大。
Moving up depthwise conv layer: 如Fig3的(c)所示,作者将depthwise换了个地方。这种变化也是有处处可言的,还是借鉴了Transformer,MSA block提供给MLP Layers先验信息。因此,作者认为这是一个自然的做法。这种做法使得FLOPs降到了4.1G,同时带来了Acc上的下降,降到了79.9% 。
Increasing the kernel size:为了大卷积核,作者做了上述准备工作,然后实验了3,5,7,9,11这5个卷积核大小的效果。这几种卷积核的FLOPs基本相同,其中 效果是最好的达到了80.6% , 的效果只有79.9% 。作者同时做了对于能力强的模型例如ResNet-200这样的大模型,效果并没有明显提升。
到这里作者也吐槽到,这些做法都是从ViT中借鉴过来的。
Micro Design
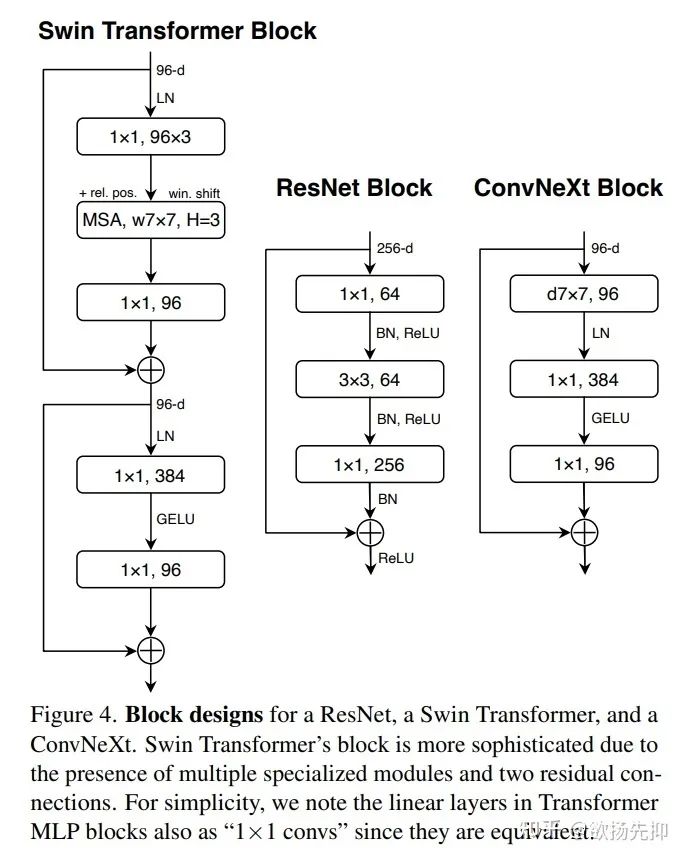
在这一部分,大多是layer层面的工作已经做完了。现在focusing到激活函数与归一化上。
Replacing ReLU with GELU: GELU比ReLU在transformer中用的更多,例如Google的BERT,还有OpenAI的GPT-2。因此,这里也将ReLU替换为了GELU,Acc没有变化,还是80.6% 。
Fewer activation fuctions: 还是transformer的设计上,没有用很多归一化函数,因此相比于ResNet Block,作者去掉了很多BN Layer,只留了一个BN Layer在 conv前。这使得Acc上升到了81.4% 。目前已经超过了Swin-T的results。作者还发现如果在Block前面加BN,并不会有Acc上的提升。
Substituting BN with LN: 作者写道,BN的存在可能会对模型的性能产生负面影响。在transformer中,用的是LN,于是作者把BN换成了LN,效果提升到了81.5% 。
Separate downsampling layers: 在ResNet中,spatial维度上的下采样是在resuidal block前面进行的,利用 stride 的卷积还有 conv stirde shortcut connection做的。在Swin中,利用的是separate downsampling layer做的,且在每两个stage之间。作者这里修改成了利用 conv layers stride 做spatial上的下采样。这次修改,效果提升到了82.0%。
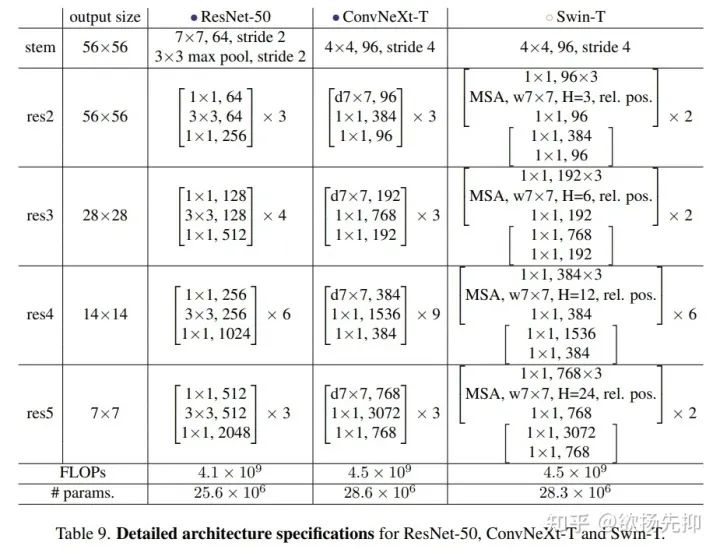
终于作者的修改到这里就结束了,这是一个纯卷积的结构,作者给其命名为ConvNeXt。下图是整体的architecture。
Results
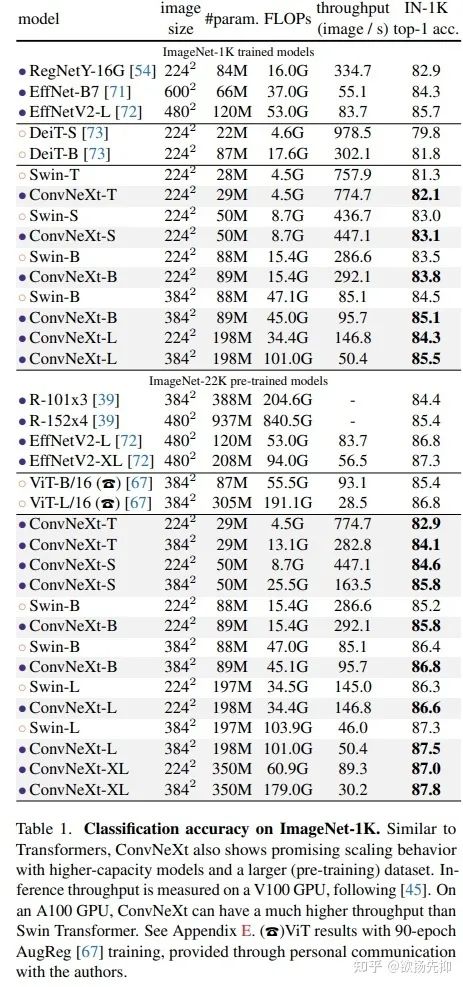
Reference
Liu, Z., Mao, H., Wu, C. Y., Feichtenhofer, C., Darrell, T., & Xie, S. (2022). A ConvNet for the 2020s.arXiv preprint arXiv:2201.03545.
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~






 京公网安备 11010802041100号
京公网安备 11010802041100号